Last month we went as fast as we could with a client to set up an infrastructure for huge amounts of data. The goal was to show that we could (a) handle all these events (b) make real-time reports and (c) combine this data with offline data for reporting.
One amazing aspect of this project was the speed. Not unlike a hackathon we gave ourselves merely days to connect many data sources, make it scale and make nice looking reports. To be honest, we were a little hesitant if it was possible. Despite that we like hackathons it felt a bit risky, but we should not have worried.
Quite often you need to convince your own organisation, and convince them we did! After the new functionality was shown, new feature requests starting coming in and everyone wanted more of delicious big data.
In this post I’ll give a short overview of what we did so far. Remember, it was all about speed so the architecture is going to evolve!
TOOLS USED
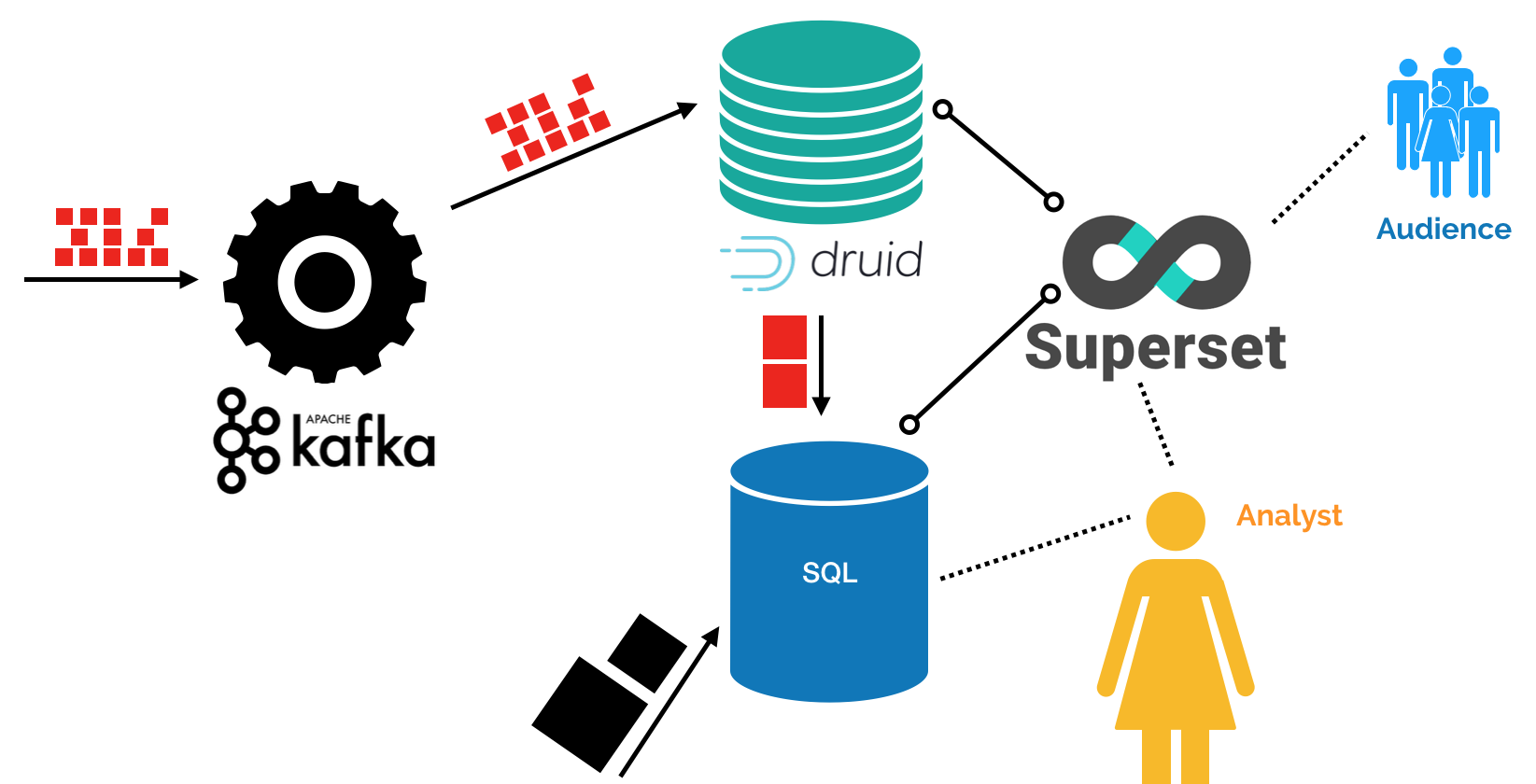
The figure below shows the tools used and how they work together. The small red blocks indicate events and the larger blocks are scheduled summaries/dumps from other systems that we want to combine.
Druid supports very fast querying so we just scheduled some queries to load the data into the SQL database for exploration and joining with other information. However, we are not completely happy with this set-up. In the future we need to process the events in more more complicated ways and we’ll introduce Spark to process events. When we do this, it’s better to let the current data stream also flow through Spark and let Druid be “just” the online analytical database for the realtime data, and we remove a dependency that’s not needed.
We used the following tools in these few days:
- Kafka to process the online events. We had high expectations and were still surprised by the performance!
- Druid is used to ingest data from Kafka and enable fast queries on the data that is coming in without delay.
- Superset to visualize the data from both SQL and the Druid cluster.
- MariaDB as SQL database, for the only reason that they already had this database.
- Airflow to schedule all kinds of tasks: getting updates from other internal systems to getting summaries from external systems.
- Programming in both Python and JavaScript for custom code to wire everything together.
LOOKING BACK
Looking back I’m particularly happy that we choose speed over almost everything else. Obviously, the functionality need to work and show it can scale, but apart from that it was just go, go, go. This allowed us to iterate very quickly, make fast decisions and fail rapidly. We learned a lot about what is needed in this organisation.
For me the main give-away is that these few days are definitely worth it! It is very hard to determine upfront what is needed for the people that actually need to work with it. As soon as they could touch, feel and smell the solution they got much sharper and improved ideas and sometimes completely flipped their requirements. Everybody wins!
Interested in touching your big data dream within a week? Contact us!