
Last week we went to Leeuwarden to hang out on a farm. Not just any farm, but the Dairy Campus. On this farm they run trials for new food and have the newest equipment. For example, cows can milk themselves and there is a manure-Roomba in the barn. Surrounded by people and cows, we analysed data on calves and milk cows and tried to come up with the worst cow puns again. The reason for the hackathon is the launch of the initiative JoinData: a platform that enables farmers, manufacturers and other companies to share data in an efficient way. It is a large cooperation of large dairy companies and they were looking for a gamechanger to showcase their platform. It was an invite only event and we were the only team from outside dairy.
FarmHackNL organised a hackathon to bring developers, farmers, programmers and data scientists together to explore the potential of having a big open database of farmers data. The hackathon had a friendly vibe and atmosphere of cowperation and sharing. Maybe that was because each of the four teams had a separate task. Four people pitched their challenge and people sorted themselves out. Most tasks had to with making data available and combine it from multiple sources, but one was about machine learning/data science. Guess which one we wanted 🙂
CRUNCHING DATA
Our task was to predict how much calves will produce once they grow up to milking cows. The-state-of-the-art models suggest that the genetics is the most critical factor in determining the milk production potential. Farmers now select calves mainly on genetics and how the calf appears. But, can we do better if we take feeding patters and other data into account? Can we make it data-driven? The figure below shows our challenge: is Annabel up for the task?
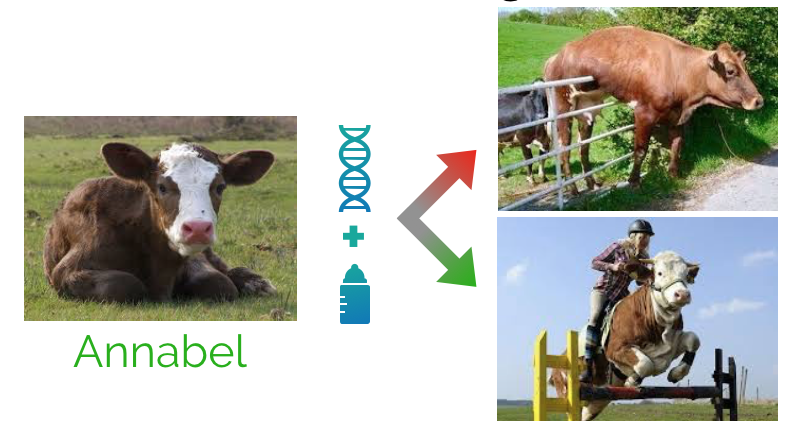
The really cool part was that we were working with data of cows on the Dairy Campus. The feeding machines of calves automatically keep track of how much they drank and how much they weight. Later, milk production when they become milking cows is also automatically measured. We could look our subjects in the eye (which we did). Looking at the data we see that milk intake as a calf is significant in the future milk production and that the feeding and weight also influence the quality of the milk. Genetic remains the main driver for success. But our results suggests that you can do better and this factor is precisely under the control of the farmer. A cool thing is that you can program the milking robot to give individual diets to cows, so you can steer the success of calves!
During the 36 hour hackathon we combined the data from two sources, cleaned it and created a predictive model (linear regression) and created an API for it. The figure below shows our pipeline:
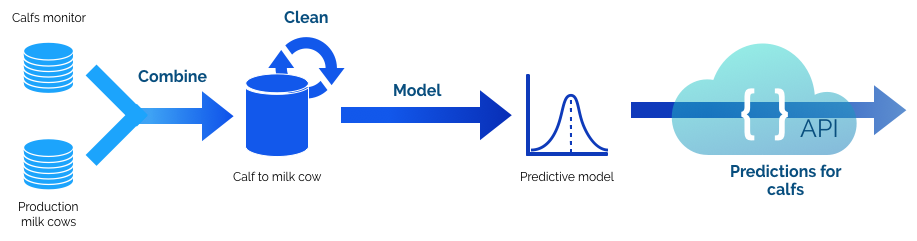
The attentive reader might also notice that our data is inherently biased: we only know the milk production of selected calfs, which were selected mainly on genetics. In the future sometimes other calves should be selected not because they have great genetics, but to really get to get sufficient data. A single farmer cannot do this in large quantities (it will be the end of his business) but as an industry you can do this. Especially if a computer helps you.
FINAL PRODUCT
Using this API farmers could get a predictor on future performance of calves when deciding which calf to keep. This should be integrated in the apps they’re already using.
DATA CLEANING
Not surprisingly we were spending most on our time connecting to datasources and cleaning it. For example, some calves weighted in at 4kg or at 600kg… The 4kg is easily explained (just one hoof on the plate), but 600kg? Additionally, sometimes calves would ‘disappear’ and the data would tell us the calf had nothing to eat or drink for weeks. Together with the domain experts in our team we filtered out cows without enough information. This left us 41 cows that we could (a) track from calf to cow (b) had sufficient datapoints to do anything sane.
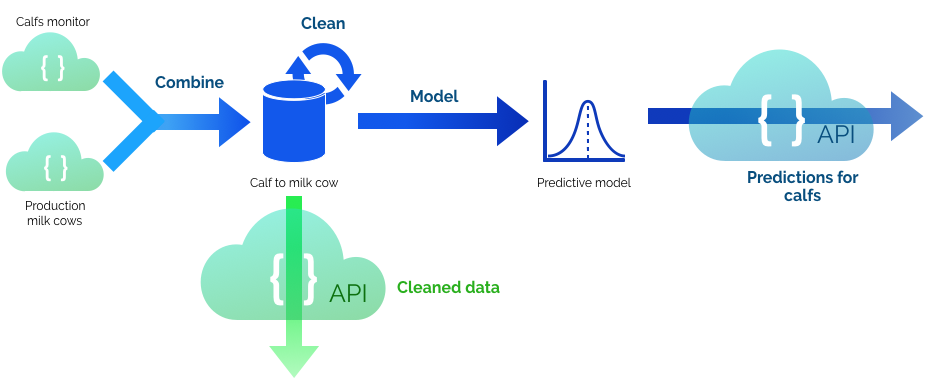
Our final mental picture is shown below. Currently the data sources we were interested in were not available through an API. Additionally, we see great value in exposing cleaned data for other applications to work on. We managed to a lot of clever things with the data and used lots of information from domain experts and knowledge of the equipment to get clean data.
CLOSING
I was excited to dive into a new industry and learn about the challenges people have working in it. Also, we had a tour of the farm: we saw the milking robots, the stands and tried on the special plastic shoes. As for the hackathon, we came in second and will talk to our new partners to bring our ideas to production.
Do you find this interesting? We too! We would love to talk about it more 🙂